



Complex, high accuracy, real-time challenges are successfully resolved by applying the right mix of 3D machine vision technologies.
The fact that 2D machine vision systems have been deployed for a few decades now is a testament to their worth. They do a perfectly good job in a wide range of applications, so there’s nothing wrong with them. There are though many production line scenarios where the practical limitations of 2D means they simply can’t be used and emerging 3D machine vision systems can.
Whether it happens to be 2D or 3D, consider any type of machine vision system, and its capability and performance in straightforward terms depends on just five principle components: the lighting, an optical lens, a digital (CMOS or CCD) image capturing sensor, image processing software tools and communication interfaces.
Now the application might involve random bin-picking, picking and placing in logistics, part inspection and measurement or a host of other tasks. Whatever automated action the system is ultimately designed to undertake, it first needs to reliably locate the target object within its field of view by comparing (and matching) its image with a predefined pattern.
→ Find the industrial 3D machine vision selector here ←
In the case of a pure 2D machine vision system, the target object image acquired for processing is effectively a flat, two-dimensional plan view. The 2D image does not provide any height information at all – there’s X and Y data, but no Z-axis depth of field data.
What we see is effectively the contours of a 3D object viewed from a specific viewpoint. Different viewpoints and different objects create entirely different contours, making 2D machine vision of limited use in applications where shape information is critical to performing a task.
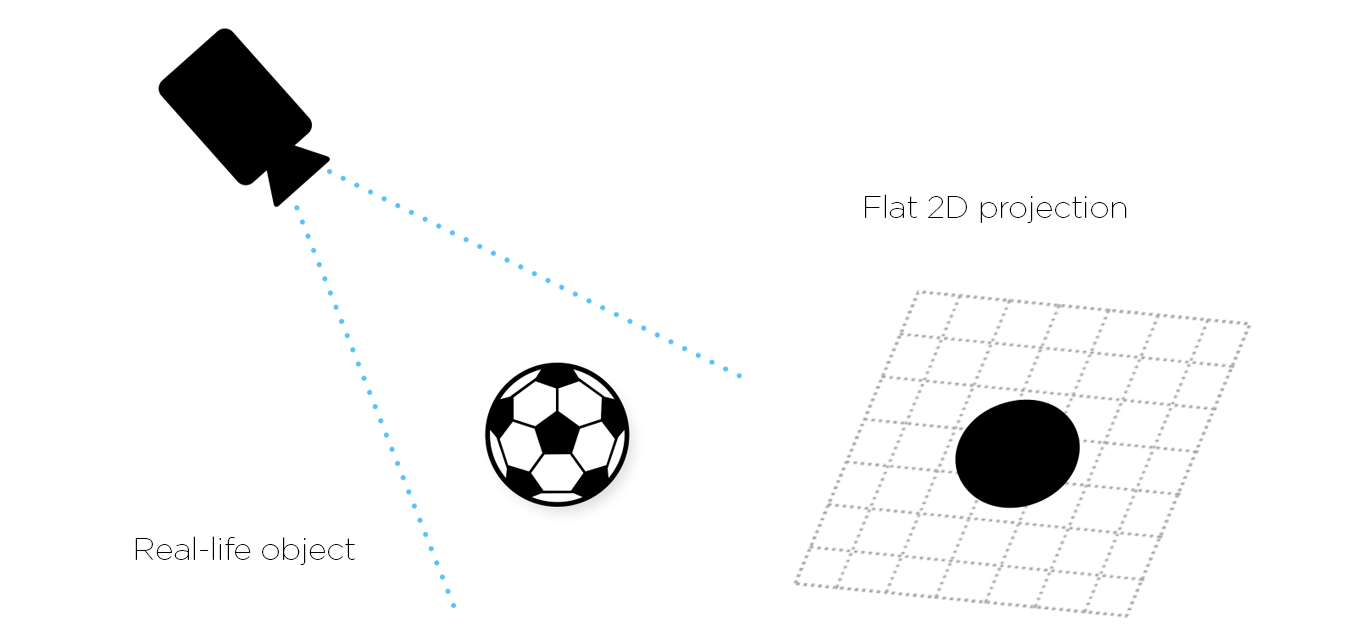
The lack of height and true shape information though is of course of no consequence for many reasonably simple applications. As a result, 2D (either area scanning or line scanning) machine vision systems are used extensively throughout the industry in a wide range of tasks. These include:
In all such applications, an accurate 2D image is derived from the variations in reflected light intensity across the target object’s surface and key features. It depends on the contrasts identified in either a grayscale or color image of the object. And here lies the first of a series of practical challenges for 2D machine vision systems.
Since the target object image is formed from light reflected from it, variations in lighting in the field of view due to changes in ambient conditions or artificial lighting can have an adverse impact on accuracy. Too much light, too little light or shadowing in the factory environment can adversely affect the clarity of edges and features appearing in the 2D plane. So sensitivity to lighting is an issue.
Moreover, since it’s those clear contrasts (and thereby clear edges and features) in the target object’s surface that 2D machine vision depends on, then it will also struggle to handle both very dark or very shiny target objects. While there are lots of different techniques for lighting up an object, its edges and features just can’t be picked out. Lack of contrast poses a problem.
Plus of course, since we’re not handling any height information with 2D machine vision, errors due to target object movement in the Z-plane presents a further limitation. If the object was always sat on a perfectly flat surface at a precise focal distance from the image sensor, then it wouldn’t be an issue for imaging accuracy.
Finally, and by definition, 2D machine vision systems as said earlier can’t cope with the intricacies of three-dimensional shape or form. Especially for complex parts and assemblies, where dimensions need to be measured other than in the X or Y plane; where a part’s volume needs to be determined; when a part needs to be picked and placed in a precise fashion, then 2D machine vision isn’t up to the task – it doesn’t recognize shape.
In a 3D machine vision system, the target object image is no longer just a flat picture. Now it’s a three-dimensional point cloud of precise coordinates where the position of every pixel in space is known. It simultaneously provides X, Y and Z plane data along with respective rotational information (around each of the axes) as well.
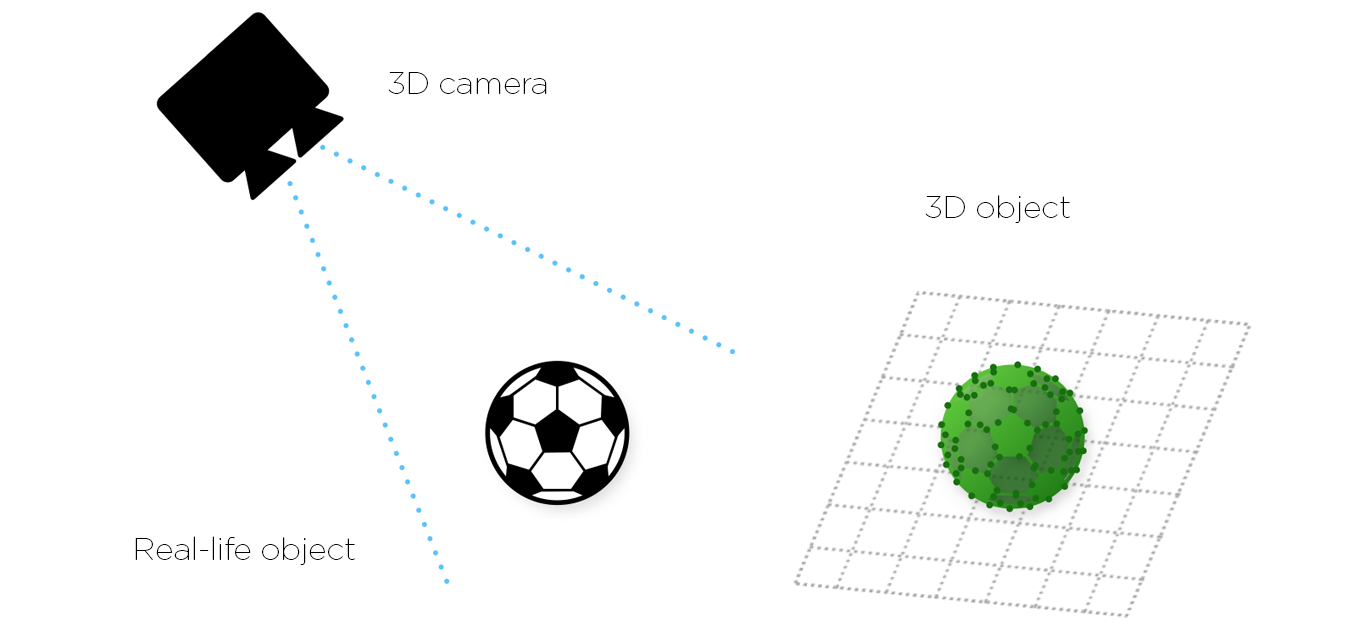
There are four main techniques for achieving 3D machine vision systems: laser triangulation; stereo vision; time-of-flight and structured light. These we’ll discuss and compare in a separate article. The Zivid 3D color cameras employs the structured light technique.
Yes, compared to two-dimensional image processing, working in 3D is indeed more time, processor and software intensive, however rapid advances in multi-core processors, 3D algorithms and software tools mean that 3D machine vision systems are now more than capable of keeping up with production line throughput requirements.
And here’s the important point. By virtue of being able to capture the extra third dimension data reliably, 3D machine vision systems are immune to the environmental factors adversely affecting 2D systems – the aspects of lighting, contrast, and distance to object discussed earlier are no longer an issue.
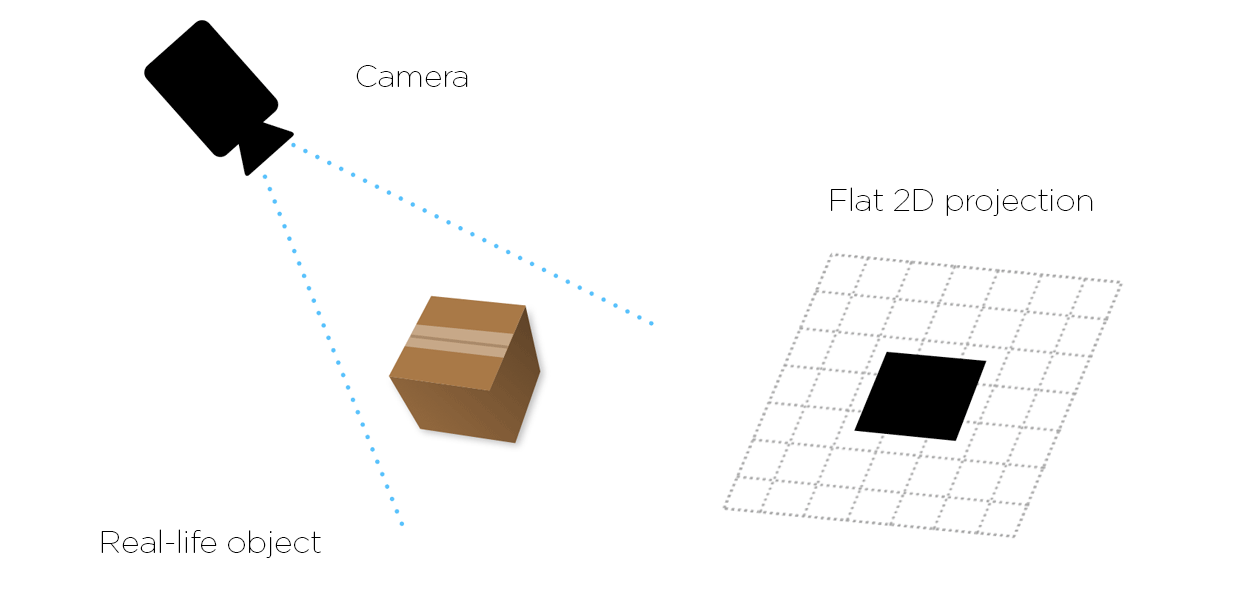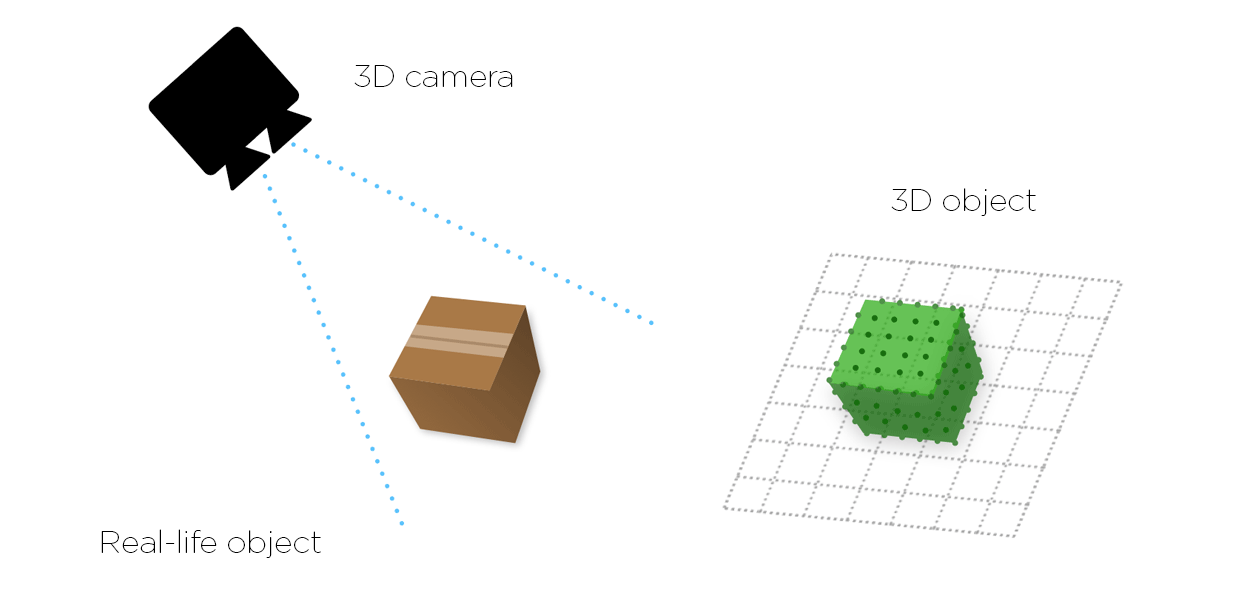
Because we’re working with a highly accurate three-dimensional digitized model of a target object our machines can now comfortably handle both shape and position. They know a target object’s precise location in space, its exact volume, surface angles, degrees of flatness and features – irrespective of production line environmental conditions and whether the object is semi-shiny or light-absorbing black. This greatly simplifies target object fixturing and overall system design.
As a result of this much-extended capability, 3D machine vision is being applied to a broad spectrum of tasks where 2D capability falls short, including amongst many:
Random bin picking, in particular, is still regarded by many as a real acid test for machine vision systems and it’s not hard to understand why.
Consider a worst-case scenario, say a bin-full of semi-bright, conical steel parts Not only does a robot need to choose an individual part from a haphazard pile and work out how best to grip it. It also needs to simultaneously take into account gripper size, the sides of the bin and adjacent parts in order to avoid collisions and entanglement.
To do this the robot needs to see the parts, and very clearly! It has to determine how they are all lying, their 3-dimensional attitude, whether they’re entirely or partly on top of one other. And if they are dark or light absorbing, shiny and reflective it needs to handle the changing scene dynamics; the reflections, missing data, and inherent noise. This process has to happen fast and accurately, time and time again. Robustness is vital.
Such complex, high accuracy, real-time challenges though are successfully resolved by applying the right mix of 3D machine vision technologies. It is providing efficient, cost-effective solutions where 2D machine vision cannot. 3D machine vision remains ‘the new kid on the block’, its rapidly developing capabilities, however, are years ahead of its age.
The quality and abilities of different 3D machine vision technologies can still though make it a challenge to choose the right tool for the job. It can be very difficult, since the data provided is far more complex than that provided by a regular camera. You need to carefully consider a lot more requirements, including resolution, color, speed, and accuracy. Also, there are the 3D measurement principles employed behind the camera. With pros and cons for each task, they too demand careful consideration.
Now it's time to read the article about active and passive 3D vision principles here, including stereo, active stereo, laser, ToF, and structured light machine vision.

